My 2 cents on ONTOLOGY
I believe that we have to standardise and integrate our data now to understand the ever-growing complexity of science projects. The application of ontologies had been trialed many times in other science domains, such as environmental modelling and ecology. The early we start to build our ontologies, the sooner we will benefit from them.
What is ontology
The term may make people think that this is just another jargon from the data science people and make them sounds like cool kids. It is not the case. ONTOLOGY is a term well defined many moons ago by World Wide Web Consortium (W3C). In short, the word ONTOLOGY in the information science domain shares a similar meaning as the word VOCABULARY. But with more formalisation in it to strictly define relationships between concepts. Therefore, less chance to form ambiguities which are the main difficulties for computers to help us integrate and merge data without much human input. For example, we know that an apple is from an apple tree, and it is probably placed in a bin or tray when the apple is picked. But computers have no common knowledge to understand information that we gained from life experience. So how can we incorporate our common sense into the system that makes computers understand the relationships between concepts and assist us to scale up our work efficiency? Ontology is the solution.
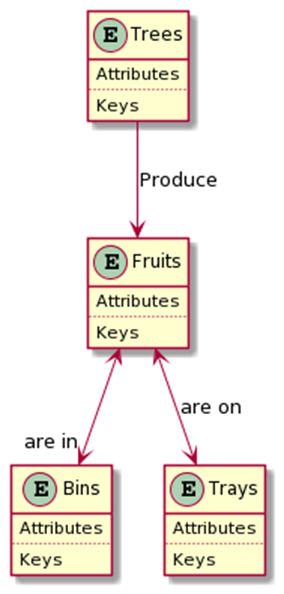
Figure below shows a realisation of an exemplar ontology for harvesting fruits. Fruits are produced by trees. We often store apple fruits either in bins or on trays depending on subsequent data collections. Each box represents a concept (or an entity or a class or a variable or whatever we like to call) with detailed descriptions (Attributes/Keys/Units etc) and relationships with other boxes (Produce, are in/on). By having this simple but exactly defined representation diagram, we can understand the whole picture. Computers can use the information as well.
Why do we need it
The entity-relationship (ER) model reveals part of the why already. This is because that we will need to clarify all the doubts and make the ontology as exact as possible before we can generate an ER model to represent the ontology statically. We will standardise our thinking, sampling protocols and all other related matters when we define the ontologies. Let’s build on the example from the figure above. Now we have two teams, A and B, that are in two different locations and want to measure fruits weight. Team A choose to use a weighing scale and labelled fruits weigh as FW with a unit kilogram. In contrast, Team B has a luxury grader that can automatically count and weigh fruits. Team B used “fruits weight” as the variable name with the grader default unit of a gram. There is no problem with the choices the two teams made given the fact that they have no idea that their data would be merged at some point to investigate spatial variations of fruits weight in these two locations. We have to invest extra time and resources to clarify the history of two data sets collected by Team A and B. The extra time and resources would be avoidable if we bring two teams together and agree on one set of protocols to conduct the data collection process.
Someone may argue that the problem could be easily solved by a grand EXCEL metadata sheet and VLOOKUP tables. In certain settings, Excel is probably a perfect solution for the task. However, this Windows-centred solution will be a nightmare when we want to capture perennial production systems with multi-year, -locations and -data types (genotype, phenotype, soil, climate, pest and disease, pollination, orchard management, consumer insights etc). Ontology seems the only viable solution that will warrant our data to meet the FAIR principles. Data collection is expensive. Why won’t we want to do a bit more than the status quo to make our valuable assets last longer and surely reusable?
How to get it
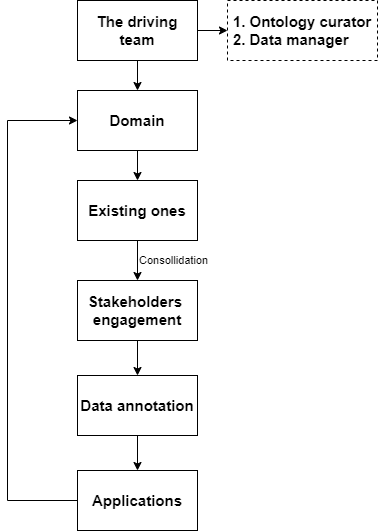
An iterative and collaborative approach will probably be the most efficient approach to build upon existing ontologies. Figure below demonstrates a flowchart of ontology development. First thing first, we need a team that has faith in ontologies to solve our data problems. Then, the team gets to choose a domain to work on. Naturally, the team will search and examine what is already there on the web, and consolidate information in hand to engage with key stakeholders. The stakeholders’ engagement step is the most critical and difficult one. Therefore, extra care might be needed to bring all stakeholders on board, especially the data collection team. The data collection teams usually have in-depth knowledge about the collection processes but are often not necessary expose to the whole life cycle of the data. A set of agreed raw ontologies will be produced by the joint efforts of all stakeholders. The second last step is data annotation, which means we can actually apply the raw ontologies to standardise our data (either historical or new). The last step is only limited by our imagination. We can develop a whole graphic knowledge database from the raw ontologies or simply format the ontologies with Web Ontology Language (OWL). Then we can move on to another domain.